This is the first post in a series of posts detailing the rationale for design choices in our motion capture glove. I will try and anticipate questions that informed users will ask. This post will cover sensors.
Why inertial (versus flex/camera/LIDAR/etc)?
Well... Capturing a human hand is a very difficult problem. We need to choose good sensors for the task. So we have to start (as always) by defining "the good". After we've done that, we can choose from the things that pass the filter.
There are the usual definitions of "good sensor" to consider... Things like resolution, dynamic range, accuracy, update rate, etc.
Then there are the considerations that are particular to our problem. We need the sensor to be where the user is all the time because many of our use-cases depend upon unbroken contact with the hand. This is to be an augmentation of the hand. And the human hand is a difficult thing to improve upon. Chasing Nature down this road will demand some things...
Wearable. This immediately disqualifies any strategy that relies on a base-station, and places inflexible constraints on the sensor's power consumption (because now we need a battery), its size (because we will hinder Nature with clunky gear), and the durability of interconnection (if applicable).
By now we've basically eliminated any form of camera or LIDAR, because the only possible mounting place where it will still retain capability is at the wrist or the forearm. The issues of environmental awareness (for the sake of removing environmental noise) and occlusion make any wearable optical strategy spotty and clunky in the best-case. Not to mention that the CPU time involved in inferring 3-space information from 2-space images is not free. It costs battery.
So that leaves us with inertial and flex, despite the fact that position is inferred data. We'll come back to this later...
So why not flex sensors?
Flex sensors are typically either piezoelectric or resistive, but the key feature they share is that they require a mechanical deformation in the sensing element to do their job. And that means that the sensing element wears out. As these sensors wear, their dynamic range worsens until sensor failure. So the sensor doesn't allow a quantifiable grasp on the world. It is a rubber ruler (quite literally).
Flex sensors are very cheap, and because the data puts very little demand on the programmer, they are easy to code for. They are also very low power. They are also attractive in a glove, because they have very low interconnection complexities, and the fingers typically only flex in the plane of the bend sensor. Typically....
However, flex sensors can't capture this:
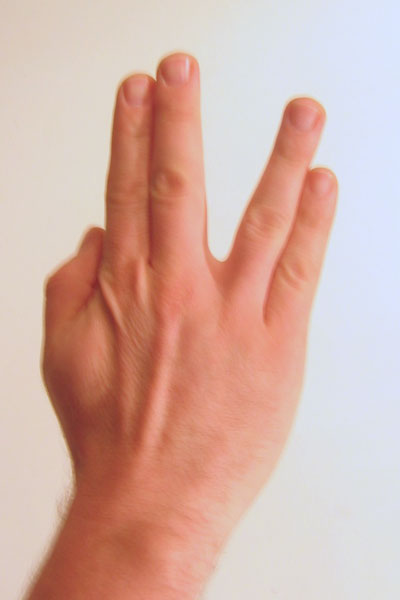
The flex strategy gives us simple data, and that is often the problem. The data is over-simplified for anything but the natural kinematic "grasp" (which is what all non-grasp mechanical strain in the sensor will be interpreted as).
We want to augment the hand. And to do that with maximum efficacy, we need good confidence in our data. We must have error-bars. Optical strategies would provide us this with aplomb, but we DQ'd them earlier as being "not good" for other reasons. See the section titled "An aside on "Good Data".
A flex sensor won't give us native units back. It will encompass all of the scaling and uncertainty associated with the ADC and EE setup surrounding them.
And that leaves inertial measurement.
So why so many sensors?
Generally: To decrease the size of our error bars. We consider 17 sensors to be the minimum count for getting good-quality data about each independently-articulated element of a hand without dependence on a software-driven kinematic map, and all of the error and floating point that it implies.
An aside on "Good Data"
This is a non-trivial question. What kinds of data do we need from a hand? Our sensor choices dictate what we get. But what do we need to do things like capture gestures of arbitrary complexity?
The first thing that we need to specify is that our data must first be able to be not only qualified (what units? what is the thing being measured?), but also quantified with a discipline that allows for quantification of error in the data. In short: Good data has both units and error-bars. With that in mind...
Many gestures and hand signs have no bearing on time whatever. They are "static"...


And yet, there is a clear difference between this....

...and this...

...so good gesture capture depends on not only position, but also momentum and rate for reasons that pertain to "linguistic after-touch", or "adverb for gestures". Sometimes, the momentum makes the movement a gesture, and acts as the trigger for a psychological gating effect that make the neural circuits of bystanders pay attention to the region for more information...

The full data stack as we apprehend it looks like this....
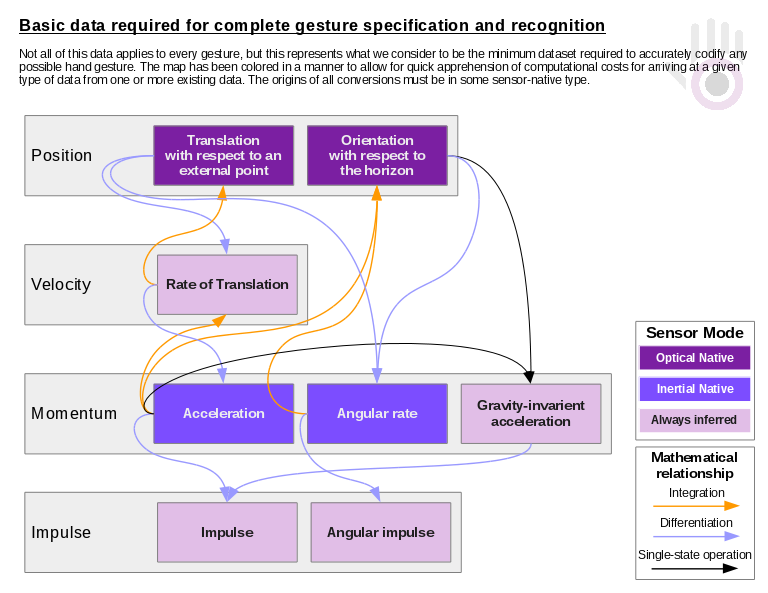
At the bottom of that stack (Momentum) is the data that we sense with IMUs. All data above it must be inferred, with the concomitant potential for errors and artifacts and the cost of computation associated with those mathematical inferences inside of very finite constraints.
But assume for a moment that we were going to sacrifice our previously-defined values, and use an optical base station, we still have a serious problem, only now we have it from the other side of velocity; perfect position, no knowledge of momentum. Momentum is always going to be inferred data for a camera.
Velocity will be inferred data regardless of an optical or inertial strategy. Either momentum or position must be the thing measured, and velocity either derived or integrated from many successive measurements.
There will always be places for both capture strategies in VR/AR. Your particular use-case will dictate the most appropriate solution. We chose IMUs for their favorable position in that data stackup.

